No More Train-Inference Mismatch: Bitwise Consistent On-Policy Reinforcement Learning with vLLM and TorchTitan
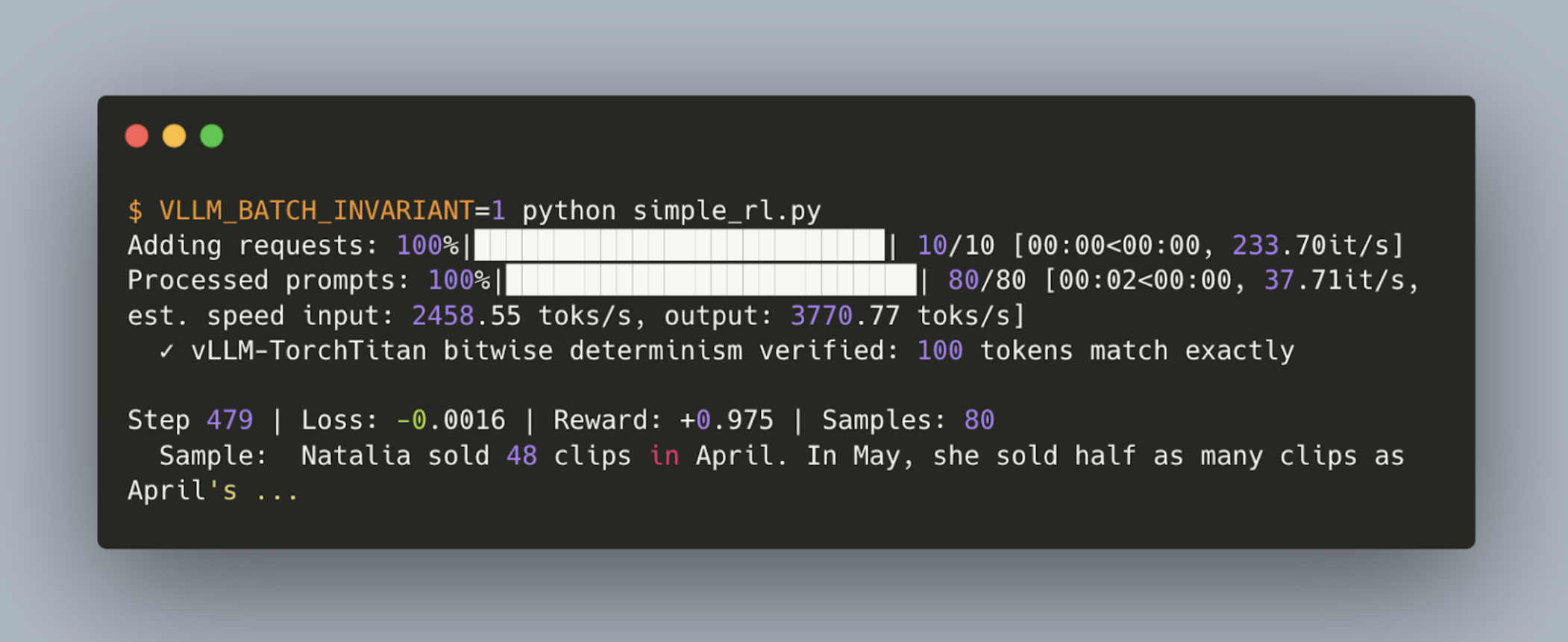
We demonstrate an open-source bitwise consistent on-policy RL run with TorchTitan as the training engine and vLLM as the inference engine. Built on top of vLLM’s recent work on batch-invariant inference, we show how to run an RL fine-tune of Qwen3 1.7B with bitwise matching training and inference numerics in our open-sourced instructions:
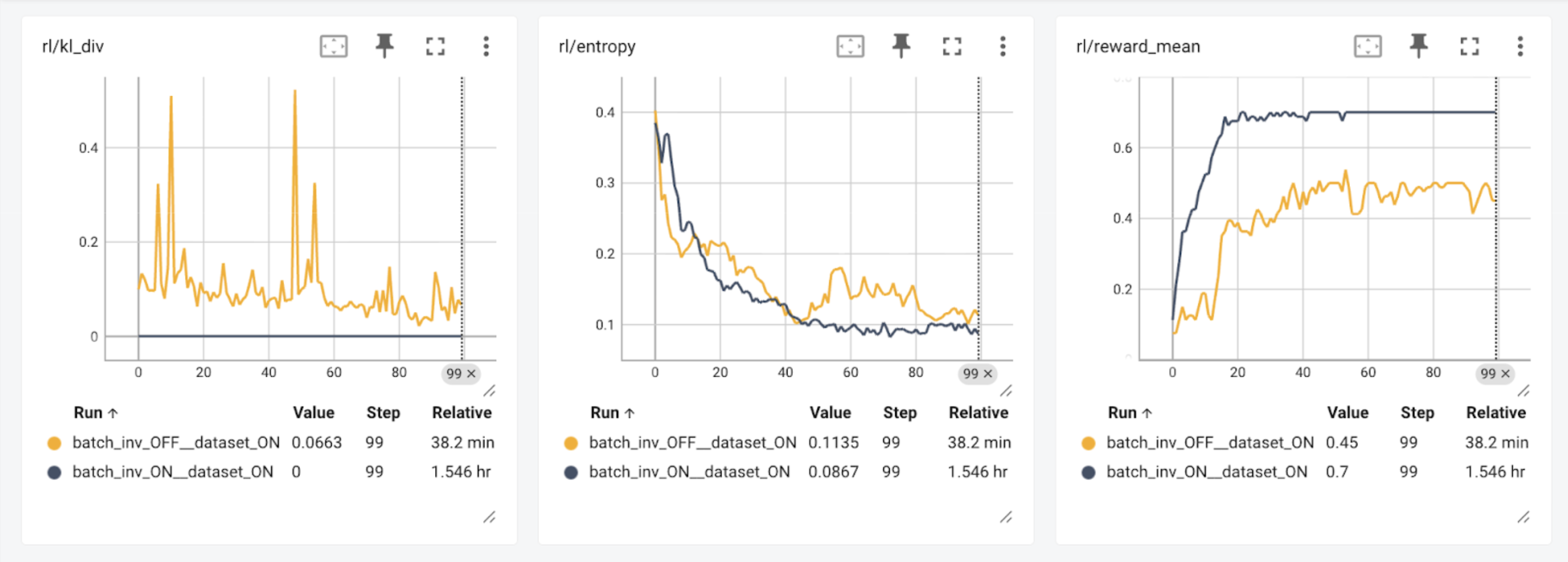
Reinforcement learning has been shown to amplify tiny numerical mismatches between trainer and sampler, leading to non-deterministic and unstable training behavior (He et al. & Yao, Liu et al.). We verified the impact of numerics on RL results with our results: Running the sampler with different kernels than the trainer (batch_inv_OFF) shows a reduced reward over 100 steps. Enabling bitwise exact training (batch_inv_ON, where kl_div always equals to 0.0), we see the model not only train in fewer steps, but reach a higher total reward.
Approach
Training and inference frameworks often use vastly different kernels because of the different workload properties. Even within an inference framework, different kernels can be chosen for different scenarios: Kernels for high batch sizes parallelize heavily on the batch dimension, while kernels for low batch sizes parallelize more within a single instance to have better utilization on parallel cores on GPUs. All these differences cause numerical differences between training and inference frameworks and lead to worse RL results.
In this work, we tackled the invariance across two different frameworks: TorchTitan as the training framework and vLLM as the inference framework. We audited every single invocation of every kernel during the forward pass to make sure they are bitwise equivalent across the frameworks. We leveraged the forward pass kernels from vLLM’s recent batch invariance work and wrote simple backward passes for these ops.
vLLM has many heavily optimized fused operations, such as the SiLU MLPs and RMSNorms (with added residuals). To maintain bitwise equivalence, we imported the exact operations for the forward passes. These operations needed custom backward passes registered, and this could be done in the same vanilla PyTorch TorchTitan is written in.
For the RL demo, we wrote a generic reinforcement learning script using GSM8K and a correctness reward. We used TorchTitan’s utilities for a trainer and wrote a custom generator. Our generator, VLLMRolloutEngine, wraps simple functionality like calling generate and updating weights. We run everything synchronously, alternating between trainer and generator on a single host. This is demonstrative of exactly on-policy execution, but is not very common in large scale runs.
What’s Next
We will continue to push forward on bitwise consistent training and inference. To follow this work, please see the linked RFC: #28326. More specifically, we will focus on the following directions:
Unified model definition. Although we have demonstrated the bitwise equivalent training and inference results, there are still two copies of the model code, one for training and one for inference. This is easy for our first integration but fragile for long-term maintenance: any slight change to each of the model code will break the equivalence between training and inference and lead to numerical mismatches. Having a shared model code for both training and inference frameworks will eliminate the possibility of introducing accidental human errors and make the bitwise matching property easier to maintain.
Compilation Support. For now, we do not use torch.compile for the TorchTitan model, and thus enforce eager mode for vLLM. It is straightforward to remove this constraint, but a torch.compile version of the TorchTitan model would need to be built. vLLM heavily leverages torch.compile and is able to maintain batch-invariance with it - but to maintain cross-framework compatibility would require a change to the trained version of the model. This will be pursued in followup work!
RL Performance Our current results show that the bitwise RL run is 2.4x slower than the non-bitwise case. We will continue to improve the performance of vLLM with better tuning of batch-invariant kernels, as well as levereaging technologies including compilation.
Wider Model Support We plan to extend this bitwise-consistent RL framework beyond Qwen3 1.7B to support other open models. We will also generalize the auditing tools and backward implementations to cover a broader range of operator types, making bitwise training-inference consistency a scalable and reusable feature.
Authors: Bram Wasti, Wentao Ye, Teja Rao, Michael Goin, Paul Zhang, Tianyu Liu, Natalia Gimelshein, Woosuk Kwon, Kaichao You, Zhuohan Li